Troubleshooting Drupal Performance - Part II
Well, overnight the site went down, so I'm back at the drawing board to see (1) what is the specific bottleneck and (2 how to fix it.
I asked GPT what are the memory requirements for (1) mysql and (2) a drupal site, the two memory-intensive things I'm running in this system. It said, I should be okay with 4Gb of RAM. As I expected.
I adjusted mysql config but it didn't help: https://github.com/wasya-co/docker_drupal/blob/0.0.0/docker-compose.yml-template#L36
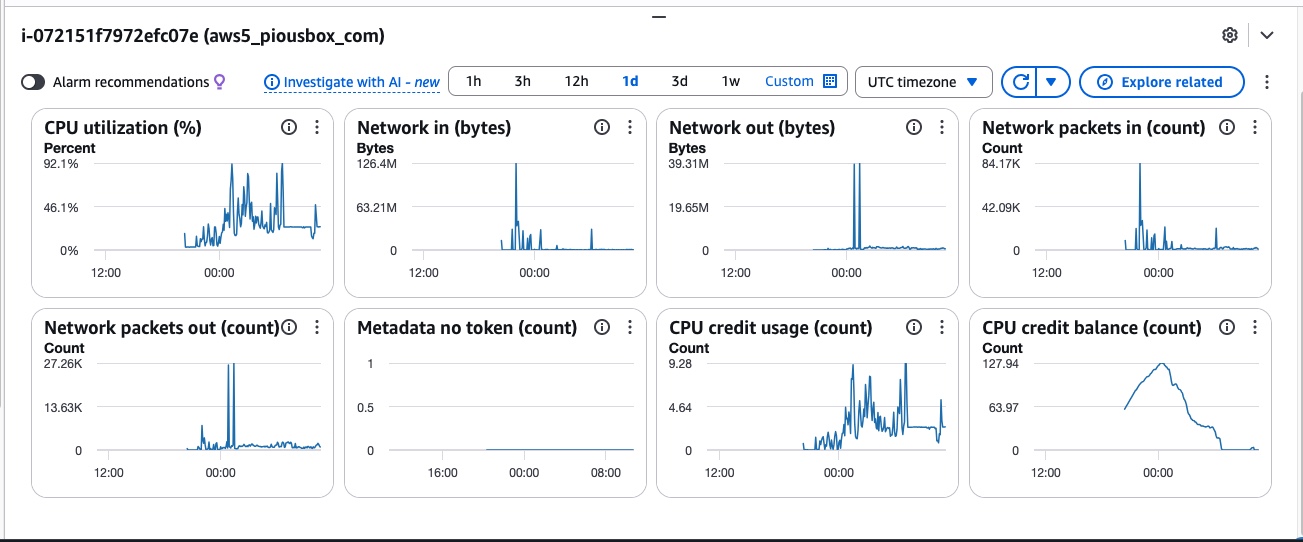
As I am also switching cloud providers around, I took another look at AWS, and they didn't perform well. So let me get this straight: AWS basic monitoring does not include memory? They don't monitor memory usage? But they track "metadata no token" which is unused, I never heart of such a thing and it sits at zero. And they track... CPU credit usage... AND CPU credit balance, apparently? :thinking: I'm just renting a compute node from them, I don't want no credits. And so my CPU utilization hit 100% once but stays at 25%, while credits go up and down and my node runs out of memory... So what they're saying is that I'm too shallow to understand this and I need a devops professional to take care of my very complicated needs? Or maybe, I think they want me to be a full-time AWS devops expert on my own, since this is obviously so important? Or maybe I can marry one, to bring it in-house. I don't want to be too critical here but their tooltip section on what CPU credits are just goes off into dark woods and spends page after page on things that are useless. This isn't dungeons and dragons (no offence). I don't need this to look like taxes with their own little versin of hell. What on earth makes them think I'd waste my time on any of this, on collecting merit badges and little CPU credits which I don't even know if they're giving me something or taking it from me, and the utilization is never at 100% so you tell me how it makes any sense. Screenshot attached:
As a side note. I'm spending more on compute than you spend on rent, and I have very little to show for it. No wonder everyone sits on monopolist social networks and noone has their own infra: it gets very complicated! At every scale level, there are unique challenges, and addressing the previous challenge doesn't help you with the next one, not much, and all you do is spin and struggle just to keep the lights on. Profit, revenue are distant dreams, but overheating, out-of-memory and other errors are very real. So yes, I can see how someone would pay five bucks to google, and give them their soul - just so they don't have to deal with this.
~ * ~ * ~ * ~
Moving on, I wanted to see if a 4Gb node on digital ocean would work better than an equivalent on aws. I have already written the deployment automation, so I should be able to just point it at a machine from a different provider, and it should work.
One of the decisions with AWS that I took is, I used root user instead of their ubuntu user. My automation was getting all tangled up in usernames and lack of permissions, so I switched to root without sudo. Coincidentally, this makes my automation immediately portable between aws and digital ocean.
The playbook for bringing up a drupal site for me looks like this: https://github.com/wasya-co/wasya_co_ansible/blob/0.0.0/playbooks/setup_all_drupal_site.yml
I rebuilt the site on a new machine with 4Gb of RAM - let's see if it stays up at least a day. The next step after that will be to aggressively cache rendered html.


